In an earlier post, I noted that the parameter estimates for a mixture model supplied by maximum likelihood methods were only part of the story. A measure of the precision of those estimates is also needed. Confidence intervals provide this measure. This post details a method for determining them.
Packages for the analysis of mixture models in R like mixdist generate confidence intervals automatically. The direct search approach, however, has proven to be more reliable for the data sets that I have been examining. In a direct search, the likelihood is calculated for each combination of parameter values over a plausible range of those parameter values.
The likelihood value of each combination is calculated by looping over a sequence of parameter values for each parameter. The interval between the values of a parameter used in the calculations should be relatively small. When small intervals are used, however, the number of combinations of parameter values for which likelihood values must be calculated increases rapidly. Direct search of the parameter space may not be practical for some applications. The direct search approach requires that a balance be struck between precision and manageability.
I have provided some R code that can be used, with some additional work, to generate confidence intervals for parameters of a simple mixture model. The mixture model assumes that the data comprises two lognormal distributions. Confidence intervals for the proportion of cases in the first model can be determined from the results produced by the code as written; the code can be modified to generate results relevant to other variables. The code follows:
#vcdata is the list of values that comprise the data
vcdata<-c(1, 2, 3, 4, etc.)
#pvec is the proportion of cases in the first distribution
pvec=seq(0.32, 0.92, by=0.02)
#seresults stores the likelihood results at different values of pvec
seresults=matrix(nrow=length(pvec), ncol=6)
# the “for” loop allows calculation of maximum likelihood at each value of pvec
for (h in 1:length(pvec)) {
#mean1vec is the sequence of mean values used for the first distribution
mean1vec = seq(0.80, 1.32, by = 0.02)
#sd1vec is the sequence of standard deviation values used for the first distribution
sd1vec=seq(0.01, 0.39, by=0.02)
#mean2vec is the sequence of mean values used for the second distribution
mean2vec=seq(1.33, 1.75, by=0.02)
#sd2vec is the sequence of standard deviations used for the second distribution
sd2vec=seq(0.01, 0.39, by=0.02)
#long calculates the number of parameter combinations that need to be examined
long<- length(mean1vec)*length(sd1vec)*length(mean2vec)*length(sd2vec)
#results holds all permutations of the parameters and the maximum likelihood
results = matrix(nrow=long, ncol=6)
#L numbers the list of maximum likelihood calculations to be undertaken
L<-1:long
#the following “for” loops obtain all desired combinations of the other parameters
i=0
for (j in 1:length(mean1vec)) {
for (m in 1:length(sd1vec)) {
for (n in 1:length(mean2vec)){
for (q in 1:length(sd2vec)){
i=i+1
#L[i] calculates the negative log likelihood for each permutation of the parameters
L[i]= -sum(log(pvec[h]*(dlnorm(vcdata, meanlog=mean1vec[j], sdlog=sd1vec[m]))+(1-pvec[h])*(dlnorm(vcdata, meanlog=mean2vec[n], sdlog=sd2vec[q]))))
# results[] stores the parameter estimates for each parameter combination
results[i,1]=L[i]
results[i,2]=pvec[h]
results[i,3]=mean1vec[j]
results[i,4]=sd1vec[m]
results[i,5]=mean2vec[n]
results[i,6]=sd2vec[q]
}
}
}
}
#the following code labels the results and compiles it in a dataframe
like<-results[,1]
p<-results[,2]
mean1<-results[,3]
sd1<-results[,4]
mean2<-results[,5]
sd2<-results[,6]
d<-data.frame(like, p, mean1, sd1, mean2, sd2)
#the data is then ordered to find the minimum negative log likelihood
o<-order(d$like)
olike<-d$like[o]
op<-d$p[o]
omean1<-d$mean1[o]
osd1<-d$sd1[o]
omean2<-d$mean2[o]
osd2<-d$sd2[o]
d2<-data.frame(olike, op, omean1,osd1,omean2,osd2)
d3<-head(d2, n=1)
#the likelihood and parameter estimates are stored for the current value of pvec
for (se in 1:6) {
seresults[h, se]=d3[,se]
}
#the code loops back to the next value of pvec
}
#the results at each value of pvec are then reported
seresults
The code determines the maximum likelihood estimates of the other parameters at each value of the proportion variable (pvec), holding that proportion variable constant during the calculations. These results can be used in an approach called the Likelihood Ratio Test to determine the confidence intervals. This approach is analogous to the evaluation of nested models discussed previously. The reduced or nested model is compared to the completed model. Let:
Lc = the negative log likelihood of the complete model, and
Lr = the negative log likelihood of the reduced model. Then,
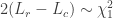
Twice the difference between the negative log likelihood of the reduced model and the complete model is approximately chi-squared distributed with one degree of freedom (since the reduced and complete models only differ by one parameter). For one degree of freedom and a tolerance of a type one error set at ten percent, the cutoff value of the chi-squared distribution is approximately 2.71. The following figure illustrates the likelihood profile for one of my data sets.

- Likelihood Profile and 90% Confidence Interval for Proportion Variable

The figure indicates that the 90 percent confidence interval for the proportion of cases in the first distribution spans from 0.49 to 0.88.
© Scott Pletka and Mathematical Tools, Archaeological Problems, 2009.
Tags: archaeology, mathematical modeling in archaeology, maximum likelihood, statistics in archaeology

Leave a comment